Infinite Images and the Latent Camera
Crossposting our Mirror piece on DALL·E 2.
This was originally posted to Mirror (with less image compression) ❤
https://mirror.xyz/herndondryhurst.eth/eZG6mucl9fqU897XvJs0vUUMnm5OITpSWN8S-6KWamY
We have had the great pleasure to be working with OpenAI InPaint and DALL·E 1 for many months, and thought it would be constructive to document some techniques, ideas and reflections that have been raised through exploring these remarkable tools in honor of the announcement and warranted public excitement around DALL·E 2.

Backstory
If you are new to this area, it is worth establishing a brief timeline of developments from the past year. In January last year OpenAI announced DALL·E, a transformer model capable of generating convincing artworks from textual descriptions. This was shortly followed by the release of OpenAI CLIP (Contrastive Language Image Pre-Training), a neural network trained on image/description pairs released for public testing.
What followed was an explosion of experimentation beginning in Spring 2021, with artists such as (but not limited to) Ryan Murdock and Rivers Have Wings releasing free and open tools for the public to play with generating artworks by connecting CLIPs capacity to discern textual prompts with open image generation techniques such as Taming Transformer’s VQGAN, and OpenAI’s own novel Guided Diffusion method.
In lay terms, to create artwork one types what one wants to see, and this combination of generator (Diffusion, VQGAN) and discriminator (CLIP) produces an image that satisfies a desired prompt. In Ryan Murdock’s Latent Visions discord group, the artist Johannez (who has been publishing artworks and tutorials around machine learning imagery and music online for years) coined the term “Promptism” for this astounding new capacity to conjure artworks from telling a neural network what one would like to see.
While this development is but the latest advancement in a legacy of machine learning in art too long to do justice to in a blog post, this act of conjuring artworks from language feels very very new. Feeling is an important dimension to the act of creating an artwork, as while we have for some years had the capacity to generate art from the laborious process of training GANs, often waiting overnight for results that invite the observer to squint and imagine a future of abundant possibility, a perfect storm in the past 18 months has led to a present in which the promise of co-creation with a machine is realized. It feels like jamming, giving and receiving feedback while refining an idea with an inhuman collaborator, seamlessly art-ing. It intuitively feels like an art making tool.
Analogies are imperfect, but this resembles the leap from the early electronic music period of manually stitching together pieces of tape to collage together a composition to the introduction of the wired synthesizer studio, or Digital Audio Workstation. In the 20th century this progress in musical tools-at-hand took place over half a century. In contrast, this leap in machine learning generated imaging tools-at-hand has gathered steam over a 3–5 year period.
This dizzying pace of development encourages reflection!
Reflections
Since Alexander Mordvintsev released the Deep Dream project in 2015, machine learning imagery is often associated with surrealism. It is no doubt surreal to find oneself co-creating art by probing a disembodied cognitive system trained on billions of datapoints, and the images produced can be confounding and psychedelic. However these are characteristics often ascribed to new experience. New experiences are weird, until they are no longer.
At the advent of DALL·E 2 we find it quite useful to think instead to the history of the Pictorialism movement.

In the early to mid 19th century, photography was the domain of a select group of engineers and enthusiasts, as it required a great deal of technical knowledge to realize photographs. As such, the focus of these efforts and gauge of the success of the medium was to create images that most accurately reflected the reality they intended to capture.
The Pictorialists emerged in the late 19th century as a movement intent not on using photographic techniques to most accurately depict reality, instead opting to use photography as a medium of communicating subjective beauty. This movement progressed photography from a scientific to an expressive medium in parallel with increasing access to cameras that required no technical expertise (the first amateur camera, the Kodak, was released in 1888).
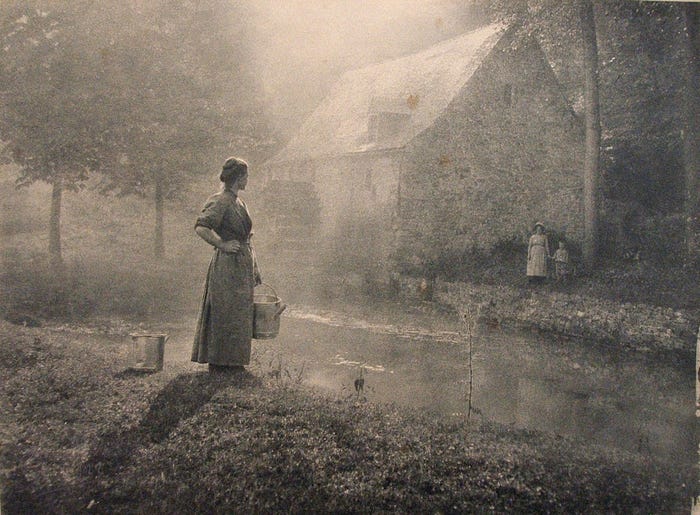
Debates raged about whether or not photography could in fact be art, a conversation inevitably dismissed once artists were able to affordably integrate cameras into their practices. The Pictorialists extolled the artistic potential of the camera by perverting its purported function of objectively capturing the world, staging scenes and experimenting with practical effects to create subjective and expressive works. Painters soon began integrating the camera into their workflow, and now most art forms make use of sensor based imaging in one form or another.
Larry Tesler’s pithy description of AI, “Artificial intelligence is whatever hasn’t been done yet.”, is equally applicable looking back to the birth of photography. Photography had also not been done yet, and was then (a phenomenon described as the AI effect) soon integrated into most artistic and industrial practices. Sensor based imaging remains a discrete focus of research pursuing things that have not been done yet.
The parallels with this time period are clear. In machine learning imagery, the laborious task to this point has been to legitimize the medium by attempting to accurately reflect the reality of training material. Great efforts have been made to realize a convincing and novel dog picture from training neural networks on dogs. This problem has been solved, and sets the foundation upon which we can begin to be expressive.
As happened with the Pictorialists, prompt based systems like DALL·E are democratizing the means by which anyone can create AI facilitated subjective art with next to no technical expertise necessary, and we assume that in the coming decades these techniques will be integrated into artistic and industrial practices to a great degree. AI will remain a discrete field of research exploring what has not been done yet, and in 2 years we will think nothing of painters using tools like DALL·E to audition concepts, or companies using tools like DALL·E to audition furniture for their office.
DALL·E represents a shift from attempts to reflect objective reality to subjective play. Language is the lens by which we reveal the objective reality known to the neural network being explored. It is a latent(hidden) camera, uncovering snapshots of a vast and complex latent space.
The same debates will rage about whether or not prompt based AI imagery can be considered Art, and will just as inevitably be relegated to history once everyone makes use of these tools to better share what is on their mind.
The ever evolving pursuit of art is greatly benefitted from reducing any friction in sharing what is on your mind. The observer is the ultimate discriminator, and as with any technological development that makes achieving a particular outcome more frictionless, creating great art that speaks to people in the time that it is made remains an elusive and magical odyssey.
The easier it is to generate artworks, the more challenging it will be to generate distinction and meaning, as it ever was. Great Art, like AI, is very often what hasn’t been explored yet.
DALL·E, reflections and infinite images
The first time we really got excited about DALL·E was in discovering its capacity to produce internally coherent images. Internal coherence can best be described as the ability to create convincing relationships between objects generated within an image.
To test this capacity, we began to use InPaint to extend images that we uploaded to the system without contributing a linguistic prompt. To achieve this, we would manually shift the viewfinder of InPaint in either direction to extend the scene.
One particularly successful test involved extending the scene of symbolist painter Charles Guilloux’s work — L’allée d’eau (1895)


As you can see, DALL·E is capable of comprehending the style and subject of the scene, and extending it coherently in all directions. Perhaps most notable is its capacity to produce reflections consistent with objects present within the image. The curvature of the trees and river is successfully reflected in the new water being generated.
This capacity for internal coherence could only happen within the (then) 512x512 pixel viewfinder of InPaint, however successfully demonstrated a capacity to produce images of potentially infinite scale by producing incremental coherent patches of an image.
We then extended this technique to produce very large pieces under the same reflective motif. The wall sized artworks below (produced with DALL·E 1 and InPaint) are we believe the largest compositions ever produced with machine learning at their time of creation.

This process of creating a patchwork of internally coherent images to form a larger composition was very challenging, quite like attempting to paint a wall sized work from the vantage point of a magnifying glass, and with no master guide to follow. As such, we used techniques like horizon lines to retain coherence.
There is something poetic to composing in this way. Attempting to extrapolate a bigger picture with only access to a small piece of it at a time feels appropriate in the broader context of AI.
We have not yet been able to experiment with DALL-E 2 and InPaint together in the same way, however assume that even more coherent and vivid images can be produced using a similar patchwork technique.
One can imagine efforts being made to increase the coherence of a larger composition by analyzing elements contained within an image outside of the scope of the InPaint viewfinder. With these developments in mind, we expect that these tools will soon contain all the elements necessary to produce limitless resolution compositions guided by language and stylistic prompts.
Co-authoring narrative worlds
We began to make a series of infinite images extending horizontally, which allude to the potential for these tools to tell stories in the tradition of tapestries or graphic novels. This sequence below is large enough in resolution to be printed well, and is a narrative that could be extended to infinity.

To return to the original idea of extending a painting to reveal more of the scene, what might it mean to be able to produce infinite worlds from a single painting or photograph? This significantly augments the capacity of what we understand of generative art, when a coherent world, or narrative, can be spawned from a single stylistic or linguistic prompt.

One can imagine narrative art forms like graphic novels or cinema being impacted from such a development. This is a particularly exciting prospect when considering the more recent development of prompt art bots being used in active Discord communities. The first of these we encountered was developed by Wolf Bear Studio for their Halloween themed art project Ghouls ‘n GANs, where discord users were invited to generate artworks via an in-thread bot, a concept more recently being experimented with by Midjourney and the artist Glassface’s iDreamer project (also in collaboration with Wolf Bear).
Bots such as these, in combination with ideas such as Simon De La Rouviere’s Untitled Frontier experiment in narrative co-authorship, augur a future of co-creation not only with artificial intelligence systems, but also more frictionlessly with one another.
This speaks to the crux of what DALL·E feels like, a tool for jamming, rapid iteration and potentially co-authored social experiences. One can imagine group storytelling sessions online and IRL that produce vivid narrative art to be replayed later or viewed from afar.
Once the friction to share what is on your mind has been eliminated, the ability to co-create social narrative art experiences at the dinner table or the theatre seems conceivable and exciting!
DALL·E 2 and Spawning
We have only been working with DALL·E 2 for a short time, however what is clear is that the system has exponentially improved in terms of generated convincing and internally coherent images guided by language and image prompts.
We plan to publish more later on what we discover, however our initial experiments have involved further experimentation with the “Holly Herndon” embedding present within OpenAI CLIP. In lay terms, Holly meets the threshold of notoriety online to have characteristic elements of her image be understood by the CLIP language/image pairing network, something we explored last year with our CLASSIFIED series of self portraits created to reveal exactly what/who CLIP understands “Holly Herndon” to be.
We propose a term for this process, Spawning, a 21st century corollary to the 20th century process of sampling. If sampling afforded artists the ability to manipulate the artwork of others to collage together something new, spawning affords artists the ability to create entirely new artworks in the style of other people from AI systems trained on their work or likeness. As Holly recently communicated at the TED conference, this opens up the possibility for a new and mind-bending IP era of Identity Play, the ability to create works as other people in a responsible, fair and permissive IP environment, something that we are exploring with the Holly+ project.

Tools like DALL·E 2 and InPaint undoubtedly propel us closer to this eventuality, evidenced by these “Holly Herndon” style memes we were able to generate in early tests.
Memes feel an appropriate medium for experimentation in this context, as any single meme maintains it’s vitality from its ability to be personalized and perpetually built upon. Memes are cultural embeddings, not dissimilar to the embeddings present within the latent space of a neural network.
Memes are a distillation of a consensual/archetypical feeling or vibe, in much the way that the “Holly Herndon” embedding with CLIP is a distillation of her characteristic properties (ginger braid and bangs, blue eyes, often photographed with a laptop), or the “Salvador Dali” embedding is a distillation of his unique artistic style.

We find personalized applications like this pretty exciting, as while DALL·E 2 (and it’s stunning variations feature we will cover at a later time) unlocks the ability to produce convincing images in art historical styles familiar to it’s training set, we feel that there could be a misconception that its utility is limited to solely recreating artistic expressions of the past.
Like the introduction of the personal camera, it is easy to imagine a near future scenario in which all amateur and professional workflows across creative industries are augmented by these tools, helping people to more clearly depict what is in their mind through common language and an ever expanding training corpus.
The 21st century is going to be wild. We will share more as we learn more! 🦾

Herndon Dryhurst Studio 2022

